Introduction to the Lakehouse architecture and Apache Iceberg
A data lakehouse architecture uses data lake table formats to bring data warehouse ease of use and query performance alongside the cost benefits of using a data lake for underlying storage.
Apache Iceberg is one such table format that removes a lot of constraints associated with Hive tables and brings data warehouse style semantics to querying data in open formats stored in a data lake.
How did Lakehouse come about?
Traditionally, we used data warehouses to query data and provide information to the business. But this bundled components together (compute engine, storage engine, table and files formats) and proved hard to scale to growing data volume demands (partly because the monolithic style means everything must be scaled rather than individual components).
Modern, cloud native warehouses separate compute and storage to accommodate this, but they still lock data in proprietary formats and can sometimes be restrictive of the types of data and analysis that can be accommodated.
Data lakes were an attempt to combat these challenges. They store data of any type and allow storage to grow independently at a scale that cannot be met by data warehouses. Data should be kept in open data formats in the data lake so that there is no vendor lock in and different compute engines can be brought to analyze the data.
However, the ability to catalog and query the data lake often depended on using a Hive metastore and using a Hive table format. This relies on essentially tracking the data that makes up a table at the directory level. So whether your underlying storage is HDFS, Amazon Simple Storage Service (S3) or another cloud object store, Hive tracked tables at the directory level.
This led to many issues, including
- For very large tables, listing operations to retrieve the objects under a directory can mean excessive time is spent developing a query plan
- Partitions that help analysts effectively query data by reducing the amount of data required to be scanned also rely on the physical layout of the stored data. This means partition evolution is hard and expensive, since entire partitions must be re-written
- Further, using a partition does not always behave as an analyst expects. They may use a predicate on a timestamp field for instance, but the underlying table would not be partitioned by this field (since timestamp would be too high cardinality). Instead it may be partitioned on derived values such as year, month and day. Now because the user has only specified timestamp in the query predicate, the partitions are of no use and a full table scan is performed
- Another limitation, is that it is only possible to do atomic swaps on partitions. This means that in situations where data is being written and read simultaneously, issues with consistency can occur
Apache Iceberg aims to remove these constraints, intending to deliver the transactional semantics and performance of a data warehouse with the cost efficiencies of a data lake.
An architecture that uses a table format such as Iceberg over data sat in HDFS, S3 or similar, brings data warehouse type semantics (such as transactions and storage abstraction) to data stored in a data lake (in open formats such as Apache Parquet). It is therefore often referred to as a Lakehouse architecture.
How Apache Iceberg works
The key step for Iceberg removing the constraints of Hive and realizing some of the benefits of a data warehouse, was to stop tracking the data that makes up your table at the directory level and instead track it at the individual object level.
This is true for Iceberg as well as other lakehouse table formats such as Apache Hudi and Delta Lake.
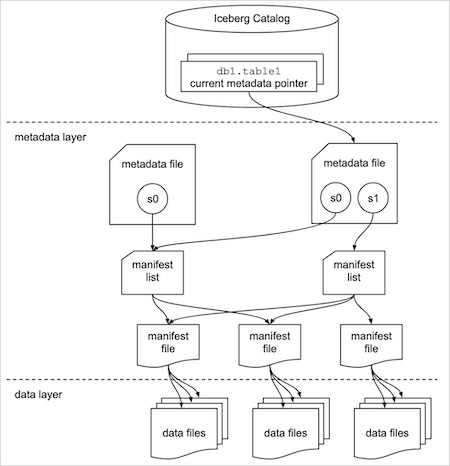
Iceberg is able to achieve this through a combination of a data layer, metadata layer and catalog. This hierarchy can be seen in the top diagram.
Data Layer
This is where the underlying data that makes up a table is stored, alongside some additional files (delete and puffin files) - we will not go into the details of these in this introduction, but one concept to be aware of is the difference between Copy on Write and Merge on Read tables.
Often, Iceberg tables are backed by cloud object storage, which is immutable. So when records are updated or deleted, we cannot go into the existing object, make the update and then save it back again. This leaves two options, with each potentially being advantageous depending on your workloads
- Copy on Write in this approach, as an update or delete is written, a new object is created with all data the same apart from the relevant update. Therefore, for write/update intensive workloads, this may not be the most efficient approach.
- Merge on Read in this approach, instead of re-writing objects, updates are written into a new object, which is read alongside the original objects during queries, and the engine uses the information to make the updates then.
Data files form part of the data layer (as seen in the diagram), and they store the table data in a supported format, often Apache Parquet.
Metadata Layer
The metadata layer consists of a DAG (directed, acyclic graph) style structure that determines which data makes up the table at any particular point in time, through the use of table snapshots. This is done through a hierarchy, extending upwards from the data layer we have:
- Manifest files which track the data layer objects and store statistics about these objects. This enables pruning without the need to open data layer objects.
- Manifest lists form the view of a snapshot of the table. The lists point to the manifest files that make up the table at that point in time and also contains statistics on the data.
- Metadata files form the top level of the metadata hierarchy and track information about the Iceberg table, in particular schema information and snapshot history as well as a pointer to the current snapshot
Catalog
The catalog helps users to find and use relevant data, it points to the current metadata file, and the catalog must support atomic operations so that table state can be kept consistent during write operations.
Key Takeaways
- Your data warehouse may struggle to scale to your required data volumes, may not offer the full spectrum of analytics you require and locks data in proprietary formats. But it abstracts away data storage offering simple querying for analysts with strong performance.
- Your data lake offers a highly scalable solution so that you can store massive data volumes at a lower cost tier compared to warehouses. However, querying this data can be tricky and using Hive tables can bring a range of issues.
- You can ingest data from the data lake into a data warehouse, but this introduces additional cost in the form of ETL processes and additional storage. It also increases copies of data.
- An effective alternative is to use a Lakehouse architecture. This brings the ease of use and performance of a data warehouse with the cost effectiveness and scale of a data lake.
- Data lake table formats such as Apache Iceberg enable the lakehouse approach and remove issues that can occur when using Hive table formats.